Continuous Integration (Part 2) – CI Server & Tools
This post was originally written for TechTownTraining blog. You can find the original article here
Introduction
In the previous post in this series on Continuous Integration (CI), we looked at the basic concepts of CI, how it helps in reducing faults while integrating software, the advantages and difficulties in adopting it and finally, how it can benefit in enforcing an Agile and DevOps team culture.
We also discussed the most common ways in which the CI fits into the development process, resulting in improved software quality, faster time-to-market, quicker feedback cycles and lower costs of development.
If you haven’t yet read the previous post, do so before you continue with this one!
In this article, we will go through the CI tools that will help in implementing a robust and beneficial CI process for your organization.
Overview
The CI server acts as the brain, working behind the scenes to seamlessly brings together various industry standard practices into the CI process implementation.
The below picture illustrates a typical CI workflow. It involves 6 stages as depicted, starting from the code check-in up until providing the feedback on that check-in to various people within the organization.
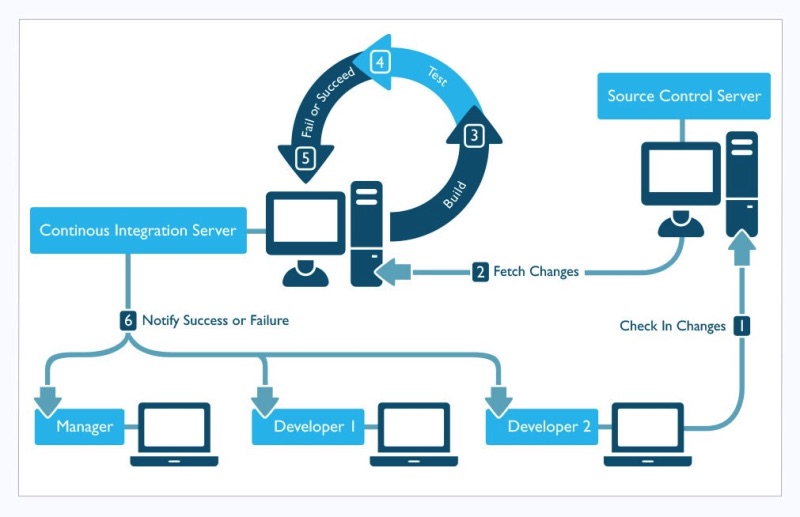
Image credit: https://insights.sei.cmu.edu
Initiate CI Process
Usually, the CI process is initiated when the developer checks-in the code into the source repository.
CI process workflows can be triggered in other ways as well, usually all the below approaches are configured to be available for development teams
- Manual – When the user manually executes the CI workflow either through the CI server admin console or through scripts
- Scheduled – Pre-configured schedule, e.g. a nightly build
- Triggered – On every commit to a source code version control system
The nightly build usually executes a larger quantity of checks on the code and takes longer to execute.
Fetch Latest Code
As the second step in the process, the CI server is responsible for fetching the latest code from the source control. This can be achieved either using the poll or push mechanism.
In the poll mechanism, the CI server is configured with the location of the source control server and its security credentials. It continuously polls the given location in regular time intervals to detect any new checkin-ins and code changes. Once it detects a change, it downloads the latest copy of the code from the source control server onto it’s own disk.
In the push mechanism, the source control system is provisioned with a ‘hook’ to the CI server. When a developer commits a change into the repository, the hook is invoked and it lets the CI server know that a change is available.
Build
The source code is usually self-contained with the build i.e. the necessary build scripts are co-located with the source code. Once the latest code is fetched as detailed in the previous step, the build is triggered using the bundled scripts.
For Java ™ projects, usually the build automation scripts use Maven or Gradle. It is uncommon to use build systems that don’t support built-in dependency management.
In cases where dependency management is not needed, “make”, a build mechanism widely used in Unix based systems is used.
There is a vast variety of other build tools available. A few are listed in the Wiki on Build automation software.
Execute Tests
In this phase of the CI process, Unit tests and Integration tests are executed. Usually, these tests are bundled along with the code as well.
For Java ™ based systems, these tests are executed using a testing framework like JUnit that allows for easy mocking of test dependencies.
Certain programming technologies may have their own test runner framework, Spring JUnit Runner in Spring, Arquillian in Java EE etc.
Running tests on CI server has the following major advantages:
- Have you ever faced a situation where the tests were passing on one machine but failing on another? By running the tests in a centralized server, we eliminate test environment issues.
- The tests execute immediately for every change and you know right away if any of the new code changes broke the expected behavior
- Most teams work on many features in parallel, possibly even with team members located and distributed globally. Every time one of the developers commits code to the repository. any failures can be identified and fixed right away.
Result
At the end of the CI process, only one of the two results are possible – the build and the tests have Failed or Passed.
Each and every check-in is verified and it is ensured that it doesn’t break the existing code. The code is built and tested as soon as it is merged into the main branch. This will allow you to decrease the amount of time your mainline code is broken.
Usually the CI server is configured to send emails (to everyone on the team or only the individual responsible for the previous check-in) in cases of failures. This way, there is quick visibility of failures and corrective measures can be taken as soon as possible.
Most CI servers also highlight the status of the most recent build and the status of last few builds in red-green-amber light indicators. Jenkins, for example, uses the following build weather indicator.
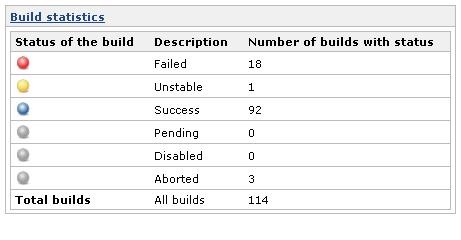
Image Source: https://wiki.jenkins-ci.org
Extending the CI Server (Using CI Tools)
The previous section highlighted the basic workflows of CI. However, most organizations also use it for many more tasks to their advantage. CI servers can be extended by installing various “plugins” to extend their behavior. Some of the most commonly used extensions are explained next.
Technical Debt & Code Quality
Any change introduced into the software will increase the complexity and disorder in the system. The measure of disorder in the system is termed as “Technical Debt”. Whenever new code is introduced into the system, the Technical Debt increases. If the technical debt is ignored for too long, getting it under control becomes almost impossible as more and more functionality is crammed with tight deadlines. This will have a negative impact on productivity and maintainability of the software.
Iterative development approach, automated tests and usage of CI to monitor the technical debt for each check-in are the only ways to keep the technical debt under control.
Tools such as SonarQube, an open source platform to identify code quality and to track technical debt should be used. It integrates easily into any CI Server, providing you access to live data on your team’s technical debt.
It also does a lot more than just measure technical debt. It measures and covers the 7 axes of code quality:
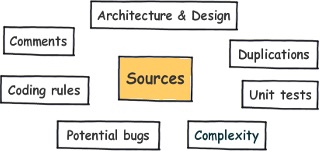
Image source: SonarQube.org
SonarQube presents the results of its analysis in an easy to understand web interface. This makes it a very useful tool not just for the developers, but also the management and other non-technical stakeholders.
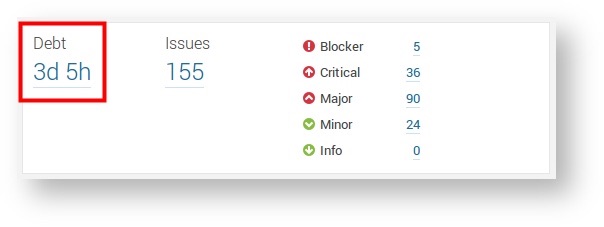
Image source: SonarQube.org
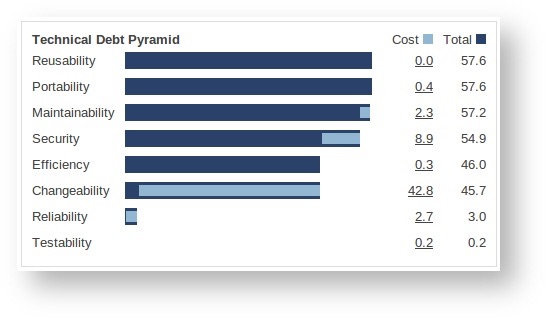
Image source: SonarQube.org
For further reading, refer to:
Semantics
Introducing CI is valuable to developers for another significant aspect – It can be used to measure Code Quality – Semantics as well as common anti-patterns.
Static code analysis tools can be utilized as part of CI process to gain insights into the health of the code. Historical data can also be stored, thereby providing a measure of the quality over a period of time. Comparisons can be drawn out between two commits to identify the measure of debt that each commit has introduced.
Many tools exist that statically analyze the code and calculate a variety of quality metrics. These tools can be incorporated into the Continuous Integration server and executed automatically.
Some of the more commonly used tools are:
- Checkstyle
- Findbugs
- Sonar
For a more exhaustive listing of tools for various platforms, refer to List of tools for static code analysis.
Code Reviews
As explained in the earlier post, the developers work on a feature branch and commit their code as often as possible.
A code analysis tool (E.g. Sonar) can be used in the continuous integration server to perform automatic code review. Each developer then takes the responsibility for addressing the review comments that were generated on their commits.
The automatic code review is based on a set of predefined rules and are a great way to find potential technical issues. These rules are available to download from all major CI vendors for most of the mainstream programming languages.
Once the automated review comments are addressed, a peer code review is carried out to catch issues that are not possible to be caught using the automated review e.g. verifying business requirements, architecture issues, whether the code is easy to read, and that it allows for easy extension.
The CI server can also be configured to block any commits to the mainline branch if a certain number of people haven’t reviewed the code. The most usual practice is to mandate a minimum of two reviewers per commit into the mainline branch. A commonly used tool for this purpose in Java ™ based projects is Gerrit.
For further listing of Code review tools for other programming languages, refer to the Wiki on List of tools for code review.
Headless Testing
If you want to run your UI tests on the CI server you’ll have to depend on headless testing because there is no display for the browser to launch in.
Headless Testing means running UI tests without the graphical user interface. Such tests require a headless browser, similar to popular web browsers, but are executed via a command-line interface and have an in-memory model of the UI elements. The in-memory model is used to simulate the interactions with the UI, for example, a click on a button in the UI is simulated to be an action on the in-memory model object.
Popular testing tools such as Selenium can be used for headless testing. Headless browsers such as PhantomJS are also widely used. By introducing these tests in the build, the CI server will be able to verify the UI for failures.
Installing CI Server
CI Servers are mainly available in three flavors:
- Standalone
- Hosted
- Private Cloud
The standalone CI server installation is made on a single machine. This is generally used for a small project or a team of fewer than 10 developers.
Hosted CI servers are available on a public cloud platform, usually based on a subscription based pricing. Most often, these go hand-in-hand with cloud-based source control systems to which the CI server has access to. These are used by companies that do not want the overhead of maintaining and upkeeping of the CI infrastructure. This is a highly viable option for mid-sized teams to get started on CI.
The private cloud is used by large companies and by those who want total control and security of their own infrastructure. Usually, multiple CI server agents are configured in a collection of high-performance servers to support the heavy workload of hundreds of developers checking-in their code.
Some of the most widely used CI servers are:
- Jenkins
- Travis CI
- TeamCity
- CruiseControl
For a more exhaustive listing of CI servers, refer to Comparison of continuous integration software.
Summary
In this post, we have covered how a CI server can be used to benefit the creation of a high-quality product. The CI server can be extended to automate the measurement of many metrics such as technical debt, code semantics, testing coverage etc.
The instantaneous feedback on the quality of the check-in ensures that faults are found quickly, ensuring that the customer gets a dependable and working product.
There are many other benefits and reasons to introduce Continuous Integration into your development process. There are much more tools to extend the CI server as well. Continuous integration is naturally complemented by Agile and DevOps methodologies of Software development.
So if you haven’t already included Continuous Integration to your process, it is never too late to do so!
Next Up
In the next post in this series on Continuous Integration, we’ll cover the key patterns and anti-patterns of implementing CI. With these suggestions, you will be able to implement the best processes for your organization’s development goals and strategies.